[八股速成]2.操作系统
前言
美团倒没怎么问操作系统。
https://blog.csdn.net/wzl1217333452/article/details/108669824
操作系统
进程与线程
说一下进程与线程的概念,以及为什么要有进程线程,其中有什么区别,他们各自又是怎么同步的
进程是资源(CPU、内存等)分配的基本单位,具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程是进程的一个实体,是独立运行和独立调度的基本单位(CPU上真正运行的是线程)。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
进程和线程的区别,你都使用什么线程模型?
1)进程和线程区别
1、一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程依赖于进程而存在。
2、进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存。(资源分配给进程,同一进程的所有线程共享该进程的所有资源。同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。)
3、进程是资源分配的最小单位,线程是CPU调度的最小单位。
4、系统开销: 由于在创建或撤消进程时,系统都要为之分配或回收资源,如内存空间、I/o设备等。因此,操作系统所付出的开销将显著地大于在创建或撤消线程时的开销。类似地,在进行进程切换时,涉及到整个当前进程CPU环境的保存以及新被调度运行的进程的CPU环境的设置。而线程切换只须保存和设置少量寄存器的内容,并不涉及存储器管理方面的操作。可见,进程切换的开销也远大于线程切换的开销。
5、通信:由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。在有的系统中,线程的切换、同步和通信都无须操作系统内核的干预 。
6、进程编程调试简单可靠性高,但是创建销毁开销大;线程正相反,开销小,切换速度快,但是编程调试相对复杂。
7、进程间不会相互影响;线程一个线程挂掉将导致整个进程挂掉。
8、进程适应于多核、多机分布;线程适用于多核。
2)常用线程模型
1、Future模型
该模型通常在使用的时候需要结合Callable接口配合使用。
Future是把结果放在将来获取,当前主线程并不急于获取处理结果。允许子线程先进行处理一段时间,处理结束之后就把结果保存下来,当主线程需要使用的时候再向子线程索取。
Callable是类似于Runnable的接口,其中call方法类似于run方法,所不同的是run方法不能抛出受检异常没有返回值,而call方法则可以抛出受检异常并可设置返回值。两者的方法体都是线程执行体。
2、fork&join模型
该模型包含递归思想和回溯思想,递归用来拆分任务,回溯用合并结果。可以用来处理一些可以进行拆分的大任务。其主要是把一个大任务逐级拆分为多个子任务,然后分别在子线程中执行,当每个子线程执行结束之后逐级回溯,返回结果进行汇总合并,最终得出想要的结果。
这里模拟一个摘苹果的场景:有100棵苹果树,每棵苹果树有10个苹果,现在要把他们摘下来。为了节约时间,规定每个线程最多只能摘10棵苹树以便于节约时间。各个线程摘完之后汇总计算总苹果树。
3、actor模型
actor模型属于一种基于消息传递机制并行任务处理思想,它以消息的形式来进行线程间数据传输,避免了全局变量的使用,进而避免了数据同步错误的隐患。actor在接受到消息之后可以自己进行处理,也可以继续传递(分发)给其它actor进行处理。在使用actor模型的时候需要使用第三方Akka提供的框架。
4、生产者消费者模型
生产者消费者模型都比较熟悉,其核心是使用一个缓存来保存任务。开启一个/多个线程来生产任务,然后再开启一个/多个来从缓存中取出任务进行处理。这样的好处是任务的生成和处理分隔开,生产者不需要处理任务,只负责向生成任务然后保存到缓存。而消费者只需要从缓存中取出任务进行处理。使用的时候可以根据任务的生成情况和处理情况开启不同的线程来处理。比如,生成的任务速度较快,那么就可以灵活的多开启几个消费者线程进行处理,这样就可以避免任务的处理响应缓慢的问题。
5、master-worker模型
master-worker模型类似于任务分发策略,开启一个master线程接收任务,然后在master中根据任务的具体情况进行分发给其它worker子线程,然后由子线程处理任务。如需返回结果,则worker处理结束之后把处理结果返回给master。
请你说一说有了进程,为什么还要有线程?
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(Inter Process Communication,IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。线程的调度与切换比进程快很多,同时创建一个线程的开销也比进程要小很多。
但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了(资源不释放会导致其他线程死锁),而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
请你说一下多进程和多线程的使用场景
多线程模型适用于I/O密集型场景,多进程模型适用于需要频繁的计算场景。
请你说一说什么是线程和进程,多线程和多进程通信方式
同一进程下的线程共享全局变量、静态变量等数据。
进程可以通过管道、套接字、系统IPC(包括消息队列、信号交互、共享内存等)等等进行通信。
常见的进程调度算法
1.先来先服务
2.时间片轮转法
3.最短进程优先
4.最高响应比优先
5.最短剩余时间优先
6.多级反馈队列算法
请问单核机器上写多线程程序,是否需要考虑加锁,为什么?
在单核机器上写多线程程序,仍然需要线程锁。因为线程锁通常用来实现线程的同步和通信。
在单核机器上的多线程程序,仍然存在线程同步的问题。因为在抢占式操作系统中,通常为每个线程分配一个时间片,当某个线程时间片耗尽时,操作系统会将其挂起,然后运行另一个线程。如果这两个线程共享某些数据,不使用线程锁的前提下,可能会导致共享数据修改引起冲突。
请你说一说多线程的同步,锁的机制
请你说一说线程间的同步方式,最好说出具体的系统调用
信号量、互斥量、条件变量
死循环+来连接时新建线程的方法效率有点低,怎么改进?
提前创建好一个线程池,用生产者消费者模型,创建一个任务队列,队列作为临界资源,有了新连接,就挂在到任务队列上,队列为空所有线程睡眠。
改进死循环:使用select epoll这样的技术。
请问怎么唤醒被阻塞的socket线程?
给阻塞时候缺少的资源
请问怎样确定当前线程是繁忙还是阻塞?
使用ps命令查看,是Process Status的缩写,列出的是当前那些进程的快照。如果想要动态的显示进程信息,可以使用top命令。
空闲的进程和阻塞的进程状态会不会在唤醒的时候误判?
请问就绪状态的进程在等待什么?
被调度使用cpu的运行权
请问线程需要保存哪些上下文,SP、PC、EAX这些寄存器是干嘛用的
线程在切换的过程中需要保存当前线程Id、线程状态、堆栈、寄存器状态等信息。
其中寄存器主要包括SP PC EAX等寄存器,其主要功能如下:
SP:堆栈指针,指向当前栈的栈顶地址
PC:程序计数器,存储下一条将要执行的指令
EAX:累加寄存器,用于加法乘法的缺省寄存器
两个进程访问临界区资源,会不会出现都获得自旋锁的情况?
假设临界区资源释放,如何保证只让一个线程获得临界区资源而不是都获得?
你说一下僵尸进程
请问怎么实现线程池
请你说一下多线程,线程同步的几种方式游戏服务器应该为每个用户开辟一个线程还是一个进程,为什么?
死锁
请你说一说死锁发生的条件以及如何解决死锁
请你讲述一下互斥锁(mutex)机制,以及互斥锁和读写锁的区别
互斥锁:一次只能一个线程拥有互斥锁,其他线程只有等待。
读写锁:可以多个读者同时进行,写者必须互斥。
C++的锁你知道几种?
说一说你用到的锁
请你说一说死锁产生的必要条件?
内存管理
说一说Linux虚拟地址空间/请问虚拟内存和物理内存怎么对应
进程不直接使用物理内存地址,而使用虚拟内存地址,即线性地址,实现进程隔离。操作系统负责将虚拟内存映射到物理内存,由内存管理单元MMU负责。
你说一说操作系统中的程序的内存结构

代码段、数据段、BSS段、堆、栈。
程序编译过程
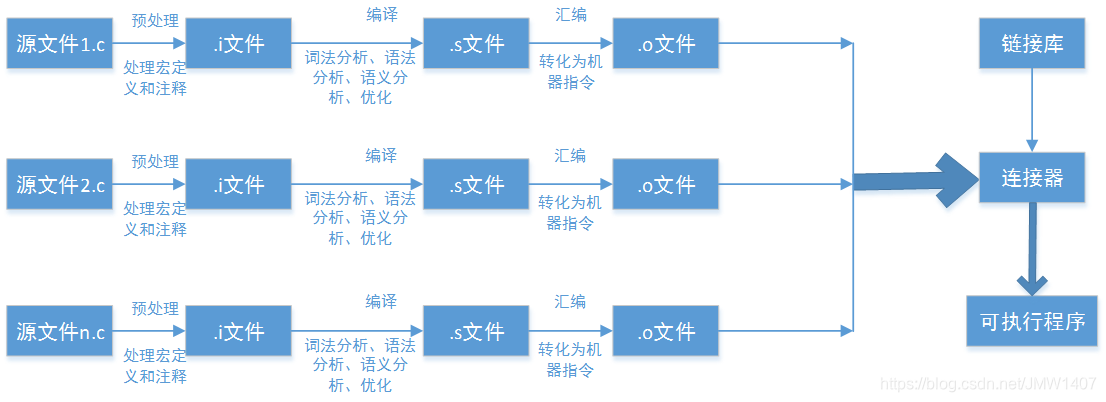
源代码(source coprede)→预处理器(processor)→编译器(compiler)→汇编程序(assembler)→目标程序(object code)→链接器(Linker)→可执行程序(executables)。
分配程序执行所需的栈空间、代码段、静态存储区、映射堆空间地址等,操作系统会创建一个进程结构体来管理进程,然后将进程放入就绪队列,等待CPU调度运行。
你说一说操作系统中的缺页中断
要访问的页不在主存,需要将其调入主存再访问。
请你说一下虚拟内存置换的方式/缺页置换算法
页面置换算法:FIFO先进先出淘汰算法,LRU最近最少使用替换算法,OPT最佳置换算法。
你说一说操作系统中的页表寻址
页表的内容就是该进程的虚拟地址到物理地址的一个映射。页表中的每一项都记录了这个页的基地址。通过页表,由逻辑地址的高位部分先找到逻辑地址对应的页基地址,再由页基地址偏移一定长度就得到最后的物理地址。
你回答一下fork和vfork的区别
vfork()会产生一个新的子进程,但是vfork创建的子进程与父进程共享数据段 ,而且由vfork创建的子进程将先父进程运行。
fork ()子进程拷贝父进程的数据段,代码段父子进程的执行次序不确定。
问如何修改文件最大句柄数?
你说一说并发(concurrency)和并行(parallelism)
问MySQL的端口号是多少,如何修改这个端口号
mysql的默认端口是3306,可以编辑用户目录下的 .my.cnf 文件进行修改。
请你说一说操作系统中的结构体对齐,字节对齐
请你说一说进程状态转换图,动态就绪,静态就绪,动态阻塞,静态阻塞
A a = new A; a->i = 10;在内核中的内存分配上发生了什么?
给你一个类,里面有static,virtual,之类的,来说一说这个类的内存分布
请你回答一下软链接和硬链接区别
请问什么是大端小端以及如何判断大端小端
请你回答一下静态变量什么时候初始化
请你说一说用户态和内核态区别
请问如何设计server,使得能够接收多个客户端的请求
windows消息机制知道吗,请说一说
请你说一说内存溢出和内存泄漏
请你来说一说协程
系统调用是什么,你用过哪些系统调用
请你来手写一下fork调用示例
请你来说一下宏内核与微内核
宏内核(不稳定、效率高):除了最基本的进程、线程管理、内存管理外,将文件系统,驱动,网络协议等等都集成在内核里面,例如linux内核。
微内核(稳定、效率低):内核中只有最基本的调度、内存管理。驱动、文件系统等都是用户态的守护进程去实现的。
请你来说一说用户态到内核态的转化原理
- 用户态和内核态是操作系统的两种运行级别,两者最大的区别就是特权级不同。用户态拥有最低的特权级,内核态拥有较高的特权级。 运行在用户态的程序不能直接访问操作系统内核数据结构和程序。
- 内核态和用户态之间的转换方式主要包括:系统调用,异常和中断。
请你说一下源码到可执行文件的过程
请问GDB调试用过吗,什么是条件断点
请你来介绍一下5种IO模型
请你说一说异步编程的事件循环
请你回答一下操作系统为什么要分内核态和用户态
请你回答一下为什么要有page \,操作系统怎么设计的page
server端监听端口,但还没有客户端连接进来,此时进程处于什么状态?
请问如何设计server,使得能够接收多个客户端的请求
Linux下怎么得到一个文件的100到200行
请你来说一下awk的使用
请你来说一下linux内核中的Timer 定时器机制